Load Balancing
Overview
Load balancing is the process by which activity in the system is evenly distributed across a network (multiple application servers) so that no single device/server is overwhelmed.
With the re-architecture of Cascade CMS, users are provided the ability to load balance multiple application servers to reduce downtime and improve performance. This involves running multiple Cascade CMS machines behind a proxy, or load balancer; typically this will be Apache. To the end user, the CMS address stays the same; behind the scenes, one of many different application servers will handle each user’s requests.
Load balancing provides concurrency; it allows for more users in the system at one time. In addition, load balancing allows the system to handle server down-time more gracefully and includes failure detection. In the event of a server failure, for example, with three Cascade CMS servers running and Apache “in-front” of it handling load balancing, Apache will simply stop sending requests to the failing server.
Please note, when using Load Balancing, it is recommended that you have all of your servers living on the same LAN.
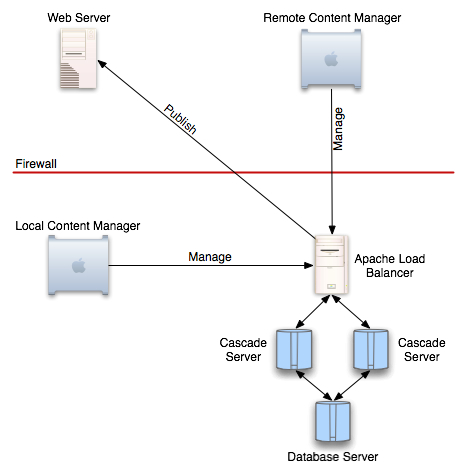
This diagram illustrates a typical CS load balanced network topology. Requests from end users are received by an Apache instance running the mod_jk module. These requests are then dispatched by mod_jk to the CS machines. The CS servers interact with the database normally. Typically one will be able to run multiple CS servers against a single database. Sometimes, depending on the configuration, it may be desirable for the database to also be load balanced; this is currently outside the scope of this document. At present, only CS load balancing is supported by Hannon Hill.
Load Balancing Requirements
- All CS machines must be running the exact same version of the software.
- Running multiple CS nodes on the same physical machine is not supported.
- When upgrading a group of CS servers, all nodes must be brought down before the software is upgraded on each node.
- Hannon Hill supports using Apache 2+ mod_jk for fail-over and load balancing.
- Each CS node name must be unique.
If you have CS deployed in something other than the ROOT webapp, you will need to ensure that your JkMount directive uses the same webapp name as the mount point.
Session replication will not be a part of the CS load balancing strategy. That means that any user sessions that are on a node will be terminated if that node is brought down. The user will see this event as being redirected to the login screen.
When running in a load balanced configuration, all servers on which Cascade CMS are running must have their internal clocks synchronized to within one second of each other. The preferred solution is to use a common NTP (Network Time Protocol) server setting on all application servers.
All servers in a load balanced configuration must have their search index location (Administration > Search Indexing > Index Location) set to a shared disk space.
Tomcat Configuration
Each CS application server runs off of an included Tomcat 8 instance. In order to enable load balancing, edit the conf/server.xml file:
Add a jvmRoute=”nodename” attribute to the <Engine.../> element:
<Engine name="Catalina" defaultHost="localhost" jvmRoute="xpproone">
The name of each node must be unique across all CS servers.
Apache Configuration
The supported load balancing configuration includes Apache 2 + mod_jk. This document assumes that Apache 2 will load mod_jk as a shared module. This document also assumes that the reader has some familiarity with configuring Apache.
Once Apache 2 and mod_jk have been built, ensure that the following configuration file changes are made:
${apache.home}/conf/httpd.conf:
LoadModule jk_module modules/mod_jk.so
JkWorkersFile workers.properties
JkShmFile mod_jk.shm
JkLogFile logs/mod_jk.log
JkLogLevel info
JkLogStampFormat "[%a %b %d %H:%M:%S %Y] "
JkMount /* loadbalancer
The JkMount directive assumes that the sole purpose of this apache instance is to proxy to a group of CS machines. If this is not the case, one may provide these directives in the context of a virtual host.
Note also that depending on how Apache is launched on your system, it may be necessary to provide full paths to the shared memory file, log file, and workers file.
${apache.home}/workers.properties:
# Define the load balancer worker
worker.list=loadbalancer
worker.xpproone.type=ajp13
worker.xpproone.host=192.168.168.128
worker.xpproone.port=8009
worker.xpproone.lbfactor=1
worker.xpprotwo.type=ajp13
worker.xpprotwo.host=192.168.168.130
worker.xpprotwo.port=8009
worker.xpprotwo.lbfactor=1
worker.loadbalancer.type=lb
worker.loadbalancer.balance_workers=xpproone, xpprotwo
The workers.properties file is the configuration file that mod_jk uses to determine where to relay requests. We’ll go over each one of the lines in this configuration:
# Define the load balancer worker
worker.list=loadbalancer
This defines the load balancer worker. It will distribute requests to each CS server.
worker.xpproone.type=ajp13
worker.xpproone.host=192.168.168.128
worker.xpproone.port=8009
worker.xpproone.lbfactor=1
Defines a worker called xpproone. This must be the same name as that node’s jvmRoute attribute in server.xml. This worker is available at 192.168.168.128. Note that the port should be the same across all instances. This worker has a load factor of 1. Higher load factors will get more requests from mod_jk.
worker.xpprotwo.type=ajp13
worker.xpprotwo.host=192.168.168.130
worker.xpprotwo.port=8009
worker.xpprotwo.lbfactor=1
Similarly defines a worker called xpprotwo. The semantics in the previous section also apply here.
worker.loadbalancer.type=lb
worker.loadbalancer.balance_workers=xpproone, xpprotwo
Defines the loadbalancer worker to be special type of worker that can distribute requests to other workers. Configures that worker to distribute its requests to xpproone and xpprotwo.
Cache Configuration
In order for caching in load balanced Cascade CMS nodes to work properly, please follow these steps:
- On each node, locate the ehcache.properties file in the directory: tomcat/conf.
- Open the file in a text editor.
- Verify whether or not your network has “multicast” enabled. If so, replace the
replication=noneproperty withreplication=multicastin Section 1. If you are unsure if multicast is enabled, you can try it out with default settings and then confirm that cache synchronization works using the steps below. If you are aware of your specific multicast settings being different than the default ones, you will need to update the properties in Section 3. - If multicast is disabled, replace the
replication=noneproperty withreplication=manualin Section 1 and proceed to Section 4 where you will need to provide current node's IP address inthisnodeaddressproperty and IP addresses of all the nodes innode{n}addressproperties where{n}is a consecutive number you can assign to each node starting from 1. It is important not to skip a number (e.g. by providing node1address and node3address but skipping node2address). - Optionally, you can change the port number the nodes will use to communicate with each other in Section 2. Change this if the default port 40001 is already taken by some other application. Change the
asyncproperty tofalseif your nodes take too long time to synchronize with each other causing data inconsistency issues. - Copy the configuration to each node. For manual replication please remember to update
thisnodeaddressproperty for each node.
rmiport setting in the ehcache.properties file (default: 40001), the cache synchronization process must be able to dynamically allocate ports between 1024 - 65536 on every node in the cluster. Firewalls must be configured to allow all traffic between nodes over this entire port range.Verifying Cache Synchronization
With nobody else accessing Cascade CMS at the time of this test, please perform the following steps:
- Verify that Index Block Rendering Cache is enabled in the Administration > Preferences > Content > Index Blocks and that the Use legacy caching strategy option is disabled.
- Log in to one node of your choice directly and create a folder Index Block with a folder selected so that at least one child asset’s name is being rendered in that Index Block when viewing it. Do not include the assets’ XML contents in your Index Block.
- View that Index Block and take note of the child asset’s name inside of the rendering.
- Log in to another node and rename that child asset.
- Log back in to the first node and refresh the Index Block rendering. Verify that the new name is being displayed now.
If you still see the old name, it means that cache synchronization is not working properly. Potential reasons:
- Your firewall does not allow your nodes to communicate with each other. Please verify that the port provided in Section 2 as
rmiportis open for communication between the nodes. Alternatively, change that port number to something else. - If your configuration uses multicast replication you might need to adjust the multicast properties in Section 3. If you are unsure if multicast is enabled in your network at this point you might be better off by configuring manual replication.
- If you are using manual replication, please make sure that all the nodes’ IP addresses are correct, nodes numbers in property names are in consecutive order and that the
thisnodeaddressproperty value is updated for each node. - If you can verify your cache synchronization works using the steps above but it does not work using some other steps (especially if these steps involve making many asset modifications in short period of time), you can try disabling the
asyncoption is Section 2 which will end up with slower execution but it will make sure that all your nodes are synchronized as soon as changes are being made instead of performing the synchronization in the background.
Tying it Together
Once configuration files have been edited, start Apache, and each Tomcat node. After the servers have been brought up, users should be able to access Cascade CMS through Apache.
Troubleshooting
I try to log in, but keep getting redirected to the login screen over and over.
This is usually a result of a misconfiguration with mod_jk. Make sure that each node’s jvmRoute attribute is set correctly, and is the name of the worker as defined in worker.properties.
I can log in, but I get automatically logged out repeatedly.
This is a common result of having asynchronized internal clocks on multiple servers. When running in a load balanced configuration, all servers on which Cascade CMS are running must have their internal clocks synchronized to within one second of each other. The preferred solution is to use a common NTP (Network Time Protocol) server setting on all application servers.